
Exciting news! As of March 2017, DAVID, our emotional voice transformation tool, is available as a free download on the IRCAM Forum, the online community of all science and art users of audio software developped in IRCAM. This new plateform will provide updates on the latest releases of the software, and better user support. In addition, we’ll demonstrate the software at the IRCAM Forum days in Paris on March 15-17, 2017. Come say hi! (and sound all very realistically happy/sad/afraid) if you’re around.
Author: Jean-Julien Aucouturier

Upcoming: Two invited talks on reverse-correlation for high-level auditory cognition
CREAM Lab is hosting a small series of distinguised talks on reverse-correlation this month:
- Wednesday 22nd March 2017 (11:00) – Prof. Fréderic Gosselin (University of Montreal)
- Thursday 23rd March 2017 (11:30) – Prof. Peter Neri (Ecole Normale Supérieure, Paris).
These talks are organised in the context of a workshop on reverse-correlation for high-level audio cognition, to be held in IRCAM the same days (on-invitation-only). Both talks are free for all, in IRCAM (1 Place Stravinsky, 75004 Paris). Details (titles, abstract) are below.
New position! Post-doctoral researcher – Psychoacoustics of musical emotions
 Position: Post-doctoral researcher (fixed-term)
Position: Post-doctoral researcher (fixed-term)
Topic: Psychoacoustics of musical emotions
Place: CREAM Lab, IRCAM (STMS, UMR9912), in central Paris (France)
Duration: 1-2 years
Contact: JJ Aucouturier (CNRS)

Corpus “Social cognition in improvised interactions”
This is a research corpus of 100 improvised musical duets recorded for the paper “Musical friends and foes: The social cognition of affiliation and control in improvised interactions” by JJ Aucouturier and Clément Canonne, Cognition, vol. 161, 94-108, 2017. http://www.sciencedirect.com/science/article/pii/S0010027717300276
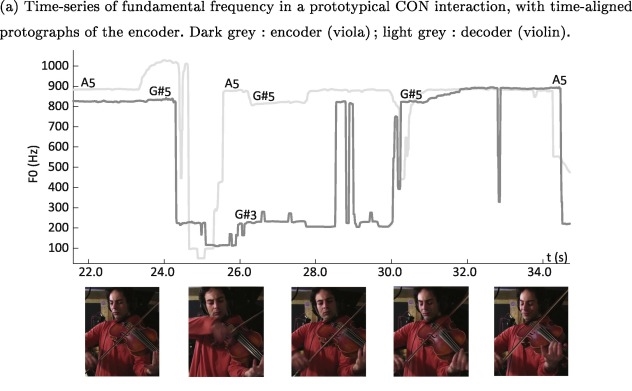
Is musical consonance a signal of social affiliation? Our new study of musical interactions, out today in Cognition
A recently emerging view in music cognition holds that music is not only social and participatory in its production, but also in its perception, i.e. that music is in fact perceived as the sonic trace of social relations between a group of real or virtual agents. To investigate whether it is at all the case, we asked a group of free collective improvisers from Conservatoire Supérieur National de Musique et de Danse de Paris (CNSMDP) to try to communicate a series of social attitudes (being dominant, arrogant, disdainful, conciliatory or caring) to one another, using only their musical interaction. Both musicians and non-musicians were able to recognize these attitudes from the recorded music.
The study, a collaboration between Clément Canonne and JJ Aucouturier, was published today in Cognition. The corpus of 100 improvised duets used in the study is also available online: http://cream.ircam.fr/?p=575
[CLOSED] Two new research internship for 2017: psychoacoustics of singing voice, and datamining of baby cries
CREAM is looking for talented master students for two research internship positions, for a duration of 5-6months first half of 2017 (e.g. Feb‐June ’17). UPDATE (Jan. 2017): The positions have now been filled.
The first position mainly involves experimental, psychoacoustic research: it is examining the link between between increased/decreased pitch in speech and singing voice and the listener’s emotional response. It will be supervised by Louise Goupil & JJ Aucouturier, and is suitable for a student with a strong interest in experimental psychology and psychoacoustics, and good acoustic/audio signal processing/music production skills. See the complete announcement here: [pdf]
The second position is a lot more computational: it involves building audio pattern recognition tools in order to datamine a large corpus of audio recordings of human infant cries for acoustical patterns informative of the babies’ development of linguistic/communicative abilities. It will be supervised by JJ Aucouturier, in collaboration with Kazuo Okanoya and Yulri Nonaka from the University of Tokyo in Japan. It is suitable for a student with strong audio machine learning/music information retrieval skills and programming experience in Matlab or (preferably) Python. See the complete announcement here: [pdf]
Applications: send a CV and cover letter by email (see announcement). Interviews for selected applicants will be held in December’16-January’17.

Workshop on Music cognition, emotion and audio technology in Tokyo
In collaboration with our friend Tomoya Nakai from Kazuo Okanoya’s laboratory in Tokyo, we are delighted to put up a one-day workshop on Music and Speech cognition, with a special focus on emotions, in Tokyo, on Monday Nov. 7th 2016.

CREAM Lab in Japan 1~8/11
Exciting news: Laura, Pablo, Emmanuel and JJ from the lab will be “touring” (the academic version thereof, at least) Japan this coming week, with two events planned in Tokyo:
- We’ll present our voice transformation software DAVID and our related research on emotional vocal feedback at the “Europa Science House” of the Science Agora event at Miraikan – Dates: Thursday 3 – Sunday 6 Nov, 10:00-17:00 / Venue: Miraikan 1F Booth Aa. This is at the kind invitation of the European Union’s Delegation in Japan.
- We co-organize a public workshop on Music cognition, emotion and audio technology with our friend Tomoya Nakai from University of Tokyo (he did all the organizing work, really), on Monday November 7th. This is hosted by Kazuo Okanoya’s laboratory.
If you’re around, and want to chat, please drop us a line. 「日本にきてとてもうれしい!!」
[CLOSED] Research internship (EEG/Speech/Emotion)
CREAM is looking for a talented master student interested in EEG and speech for a spiffy research internship combining Mismatch Negativity and some of our fancy new voice transformations technologies (here and there). The intern will work under the supervision of Laura Rachman and Jean-Julien Aucouturier (CNRS/IRCAM) & Stéphanie Dubal (Brain & Spine Institute, Hopital La Salpétrière, Paris).
See the complete announcement here: internship-annonce
Duration: 5-6months first half of 2017 (e.g. Feb‐June ’17).
Applications: send a CV and cover letter by email to Laura Rachman & JJ Aucouturier (see announcement). Interviews for selected applicants will be held in November‐December 2016.

The overdub corpus
A corpus of free pop music recordings, mixed by a professional sound engineer in several variants used to experiment with a listener’s feelings of social cohesion. Each track is available in X variants
- Single lead voice + orchestra (PBO) – drums
- Single lead voice + vocal overdub (double-tracking) + orchestra (PBO)
- Single lead voice – overdub + orchestra + drums
- Single lead voice + randomly detuned PBO – drums
- Single lead voice + randomly desynchronized PBO
The corpus is made available under a Creative Commons licence, from archive.org.
Mixed by Sarah Hermann (CNSMDP, Paris) at IRCAM, July 2016.
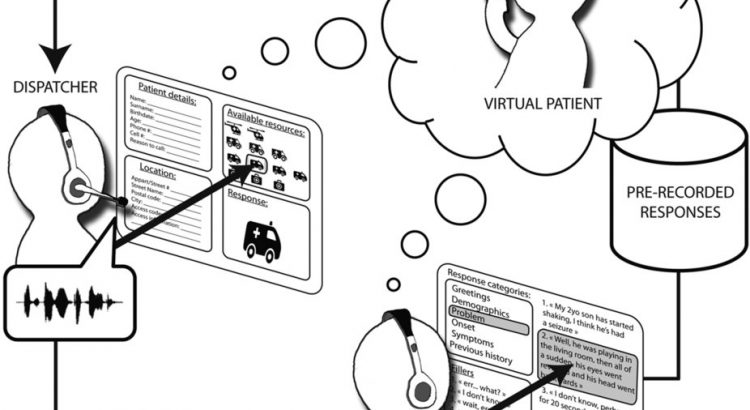
Bullying the doc: stronger-sounding patients get more 911 attention
Our team published a new paper this week, in which we test the influence of patients’ tone of voice on medical decisions.
In the line of our recent real-time emotional voice transformations, we manipulated the voice of (fake) patients calling a 911 phone simulator used for training (real) medical doctors, to make them sound more, or less, physically dominant (with deeper, more masculine voices corresponding to lower pitch and greater formant dispersion, see e.g. Sell, A. et al. Adaptations in humans for assessing physical strength from the voice. Proceedings of the Royal Society of London B: Biological Sciences, 277(1699), 3509–3518 (2010) – link).
We found that patients whose voice signalled physical strength obtained a higher grade of response, a higher evaluation of medical emergency and longer attention from medical doctors than callers with strictly identical medical needs whose voice signaled lower physical dominance.
The paper, a collaboration with Laurent Boidron M.D. and his colleagues at the Department of Emergency Medicine of the Dijon CHU Hospital/Université de Bourgogne, was published last tuesday in Scientific Reports (link, pdf).