
C.L.E.E.S.E. (Combinatorial Expressive Speech Engine) is a tool designed to generate an infinite number of natural-sounding, expressive variations around an original speech recording. More precisely, C.L.E.E.S.E. creates random fluctuations around the file’s original contour of pitch, loudness, timbre and speed (i.e. roughly defined, its prosody). One of its applications is the generation of very many random voice stimuli for reverse correlation experiments, or whatever else you fancy, really.

Voice transformation tool DAVID now available on the IRCAM Forum!
Exciting news! As of March 2017, DAVID, our emotional voice transformation tool, is available as a free download on the IRCAM Forum, the online community of all science and art users of audio software developped in IRCAM. This new plateform will provide updates on the latest releases of the software, and better user support. In addition, we’ll demonstrate the software at the IRCAM Forum days in Paris on March 15-17, 2017. Come say hi! (and sound all very realistically happy/sad/afraid) if you’re around.

Upcoming: Two invited talks on reverse-correlation for high-level auditory cognition
CREAM Lab is hosting a small series of distinguised talks on reverse-correlation this month:
- Wednesday 22nd March 2017 (11:00) – Prof. Fréderic Gosselin (University of Montreal)
- Thursday 23rd March 2017 (11:30) – Prof. Peter Neri (Ecole Normale Supérieure, Paris).
These talks are organised in the context of a workshop on reverse-correlation for high-level audio cognition, to be held in IRCAM the same days (on-invitation-only). Both talks are free for all, in IRCAM (1 Place Stravinsky, 75004 Paris). Details (titles, abstract) are below.
New position! Post-doctoral researcher – Psychoacoustics of musical emotions
 Position: Post-doctoral researcher (fixed-term)
Position: Post-doctoral researcher (fixed-term)
Topic: Psychoacoustics of musical emotions
Place: CREAM Lab, IRCAM (STMS, UMR9912), in central Paris (France)
Duration: 1-2 years
Contact: JJ Aucouturier (CNRS)

Corpus “Social cognition in improvised interactions”
This is a research corpus of 100 improvised musical duets recorded for the paper “Musical friends and foes: The social cognition of affiliation and control in improvised interactions” by JJ Aucouturier and Clément Canonne, Cognition, vol. 161, 94-108, 2017. http://www.sciencedirect.com/science/article/pii/S0010027717300276
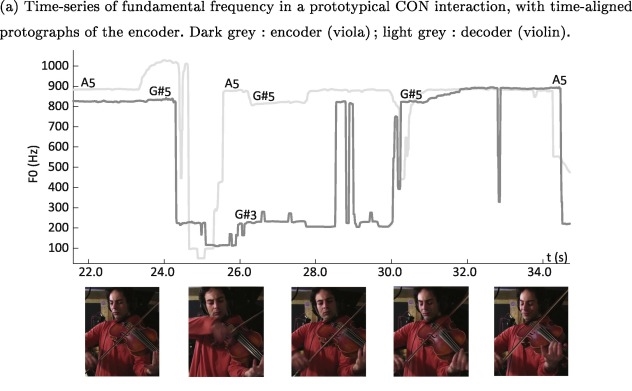
Is musical consonance a signal of social affiliation? Our new study of musical interactions, out today in Cognition
A recently emerging view in music cognition holds that music is not only social and participatory in its production, but also in its perception, i.e. that music is in fact perceived as the sonic trace of social relations between a group of real or virtual agents. To investigate whether it is at all the case, we asked a group of free collective improvisers from Conservatoire Supérieur National de Musique et de Danse de Paris (CNSMDP) to try to communicate a series of social attitudes (being dominant, arrogant, disdainful, conciliatory or caring) to one another, using only their musical interaction. Both musicians and non-musicians were able to recognize these attitudes from the recorded music.
The study, a collaboration between Clément Canonne and JJ Aucouturier, was published today in Cognition. The corpus of 100 improvised duets used in the study is also available online: http://cream.ircam.fr/?p=575
[CLOSED] CREAM is looking for a new RA ! (part-time, 5-months)
UPDATE (Feb. 2017): THE POSITION HAS BEEN FILLED.
Assistant de recherche pour passation d’expériences de psychologie cognitive
Période: Mars à Juillet 2017
Nous cherchons à engager en contrat CDD à temps partiel un ou une assistant/e de recherche pour la passation de plusieurs expériences de psychologie et neurosciences cognitive sur le thème de la voix, de la perception de soi, de la musique, et des émotions, sur la période de Mars à Juillet 2017.
La personne recrutée travaillera en collaboration avec les chercheurs ayant conçu les expériences et sera responsable de la collecte de données, en autonomie. La passation d’expérience se passera au Centre Multidisciplinaire des Sciences Comportementales Sorbonne Universités-INSEAD (6 rue Victor Cousin, 75005 Paris).
Profil souhaité
- Licence ou master de psychologie expérimentale/neurosciences ou equivalent.
- OBLIGATOIRE: avoir une expérience de la collecte de données expérimentales en psychologie/neurosciences (avoir fait passer au moins N = 20 participants adultes dans le cadre de ses études, d’un stage ou d’un contrat précédent), incluant la signature de consentement de participation, l’explication du protocole au participant, la veille au bon déroulement technique de l’expérience, la sauvegarde appropriée des différents fichiers de données, et le debriefing avec le participant.
- FORTEMENT SOUHAITÉ: avoir une expérience en psychoacoustique et/ou en traitement du signal audio.
- SOUHAITÉ: avoir un intérêt pour la recherche en psychologie/neurosciences cognitive, en particulier dans le domaine des neurosciences musicales, de la conscience de soi et des émotions et/ou avoir un intérêt pour les technologies de la musique et du son.
Conditions
Contrat: CDD CNRS niveau assistant ingénieur (AI) ou ingénieur d’étude (IE), selon diplôme et experience.
Durée: 5 mois sur la période Mars – Juillet 2017.
Quotité: temps-partiel souhaité (50 ou 60%).
Lieu de travail: Paris (France).
Rémunération: correspondant à 1821.83e mensuel brut (AI) à 2465.67e mensuel brut (IE), selon diplôme et expérience) pour un temps plein.
Envoyer un CV et lettre de motivation détaillant vos expériences précédentes de collecte de données par email à Louise Goupil lougoupil@gmail.com & Jean-Julien Aucouturier aucouturier@gmail.com.
[CLOSED] Two new research internship for 2017: psychoacoustics of singing voice, and datamining of baby cries
CREAM is looking for talented master students for two research internship positions, for a duration of 5-6months first half of 2017 (e.g. Feb‐June ’17). UPDATE (Jan. 2017): The positions have now been filled.
The first position mainly involves experimental, psychoacoustic research: it is examining the link between between increased/decreased pitch in speech and singing voice and the listener’s emotional response. It will be supervised by Louise Goupil & JJ Aucouturier, and is suitable for a student with a strong interest in experimental psychology and psychoacoustics, and good acoustic/audio signal processing/music production skills. See the complete announcement here: [pdf]
The second position is a lot more computational: it involves building audio pattern recognition tools in order to datamine a large corpus of audio recordings of human infant cries for acoustical patterns informative of the babies’ development of linguistic/communicative abilities. It will be supervised by JJ Aucouturier, in collaboration with Kazuo Okanoya and Yulri Nonaka from the University of Tokyo in Japan. It is suitable for a student with strong audio machine learning/music information retrieval skills and programming experience in Matlab or (preferably) Python. See the complete announcement here: [pdf]
Applications: send a CV and cover letter by email (see announcement). Interviews for selected applicants will be held in December’16-January’17.

Workshop on Music cognition, emotion and audio technology in Tokyo
In collaboration with our friend Tomoya Nakai from Kazuo Okanoya’s laboratory in Tokyo, we are delighted to put up a one-day workshop on Music and Speech cognition, with a special focus on emotions, in Tokyo, on Monday Nov. 7th 2016.